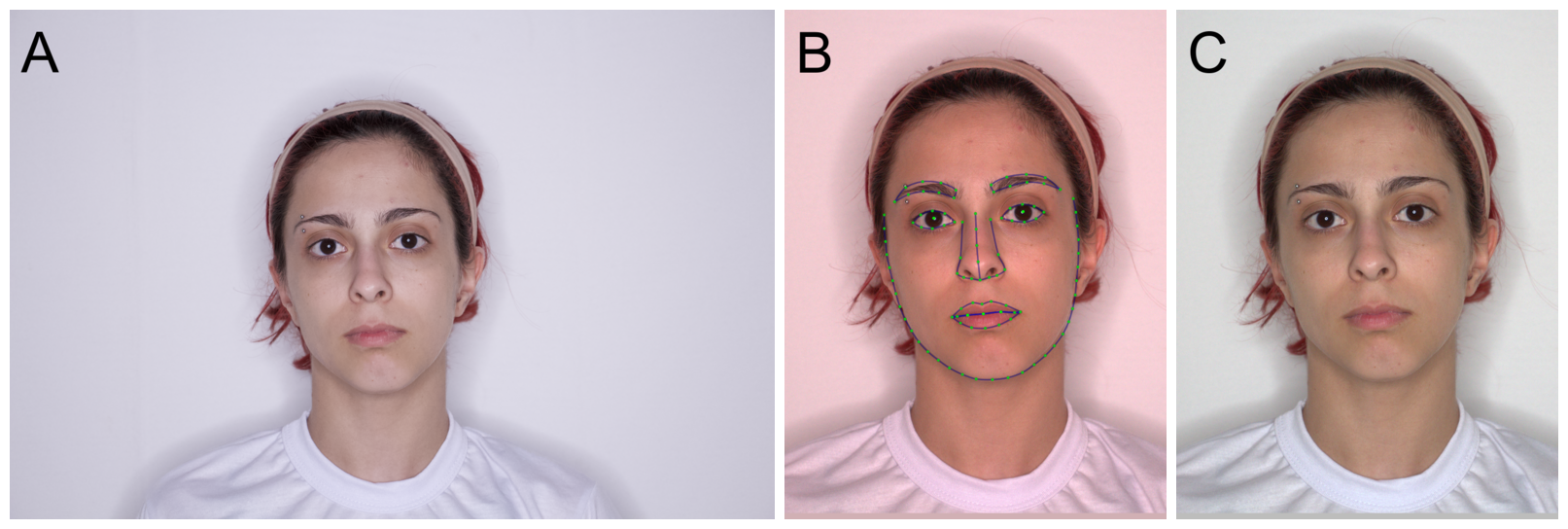
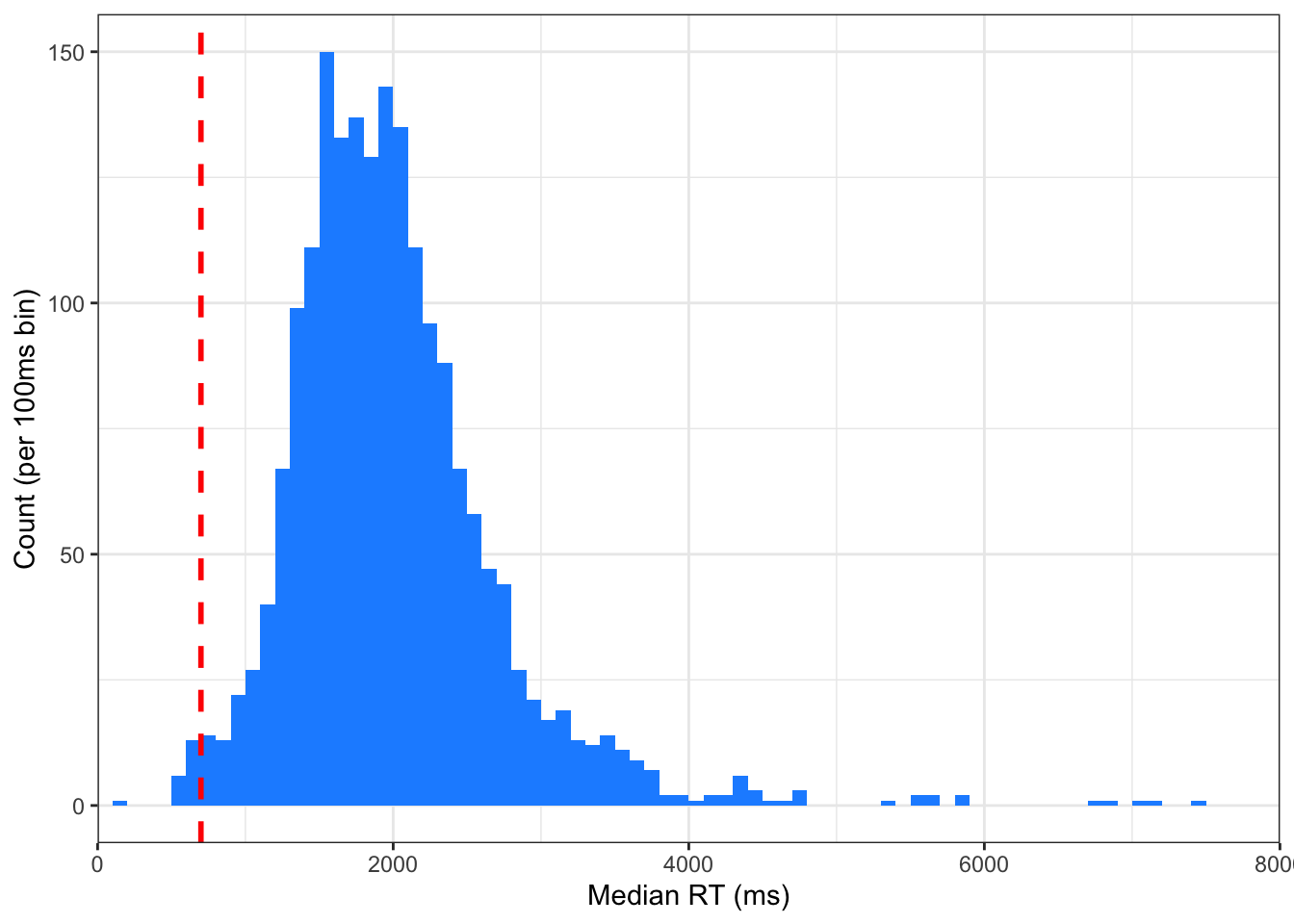
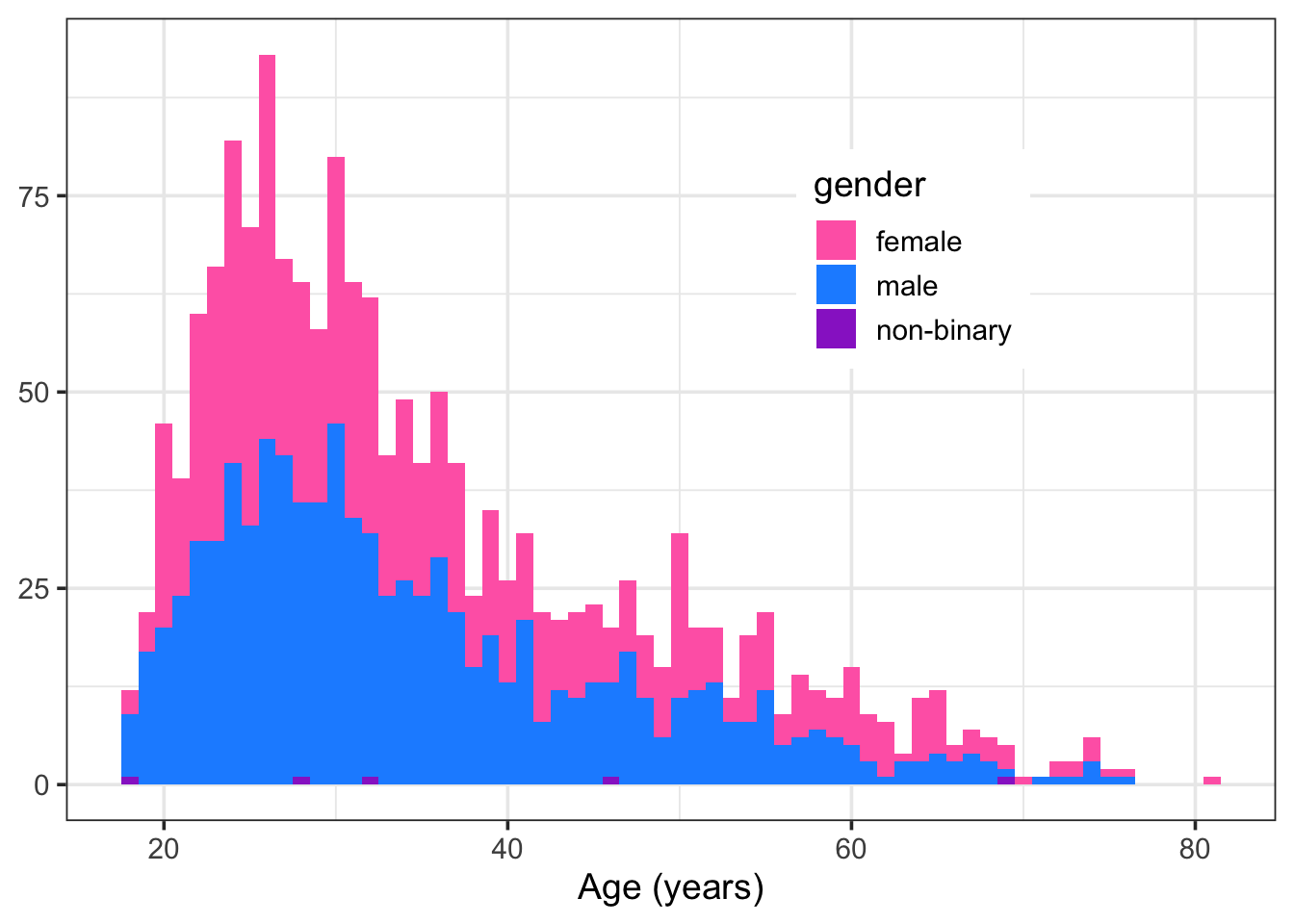
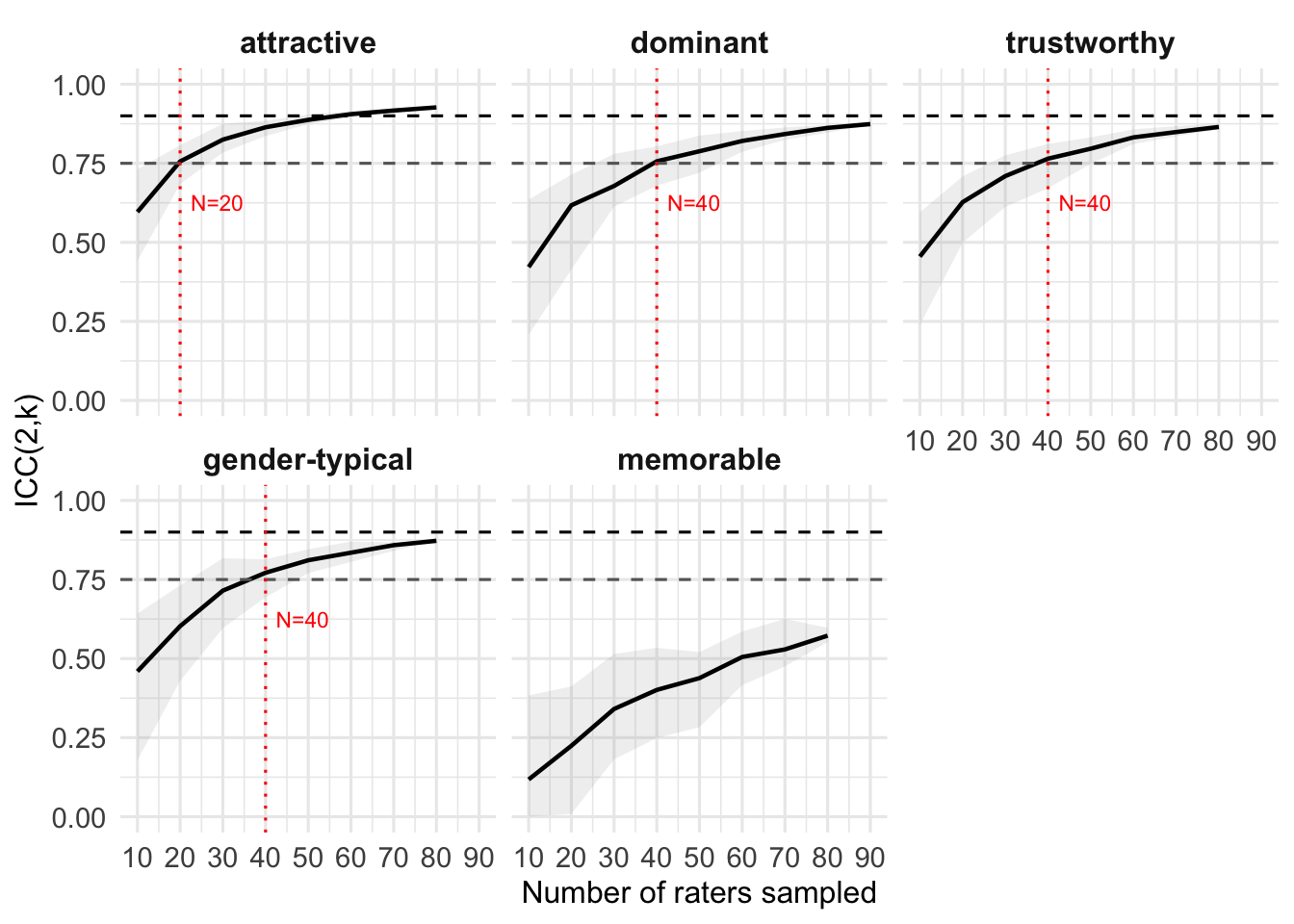
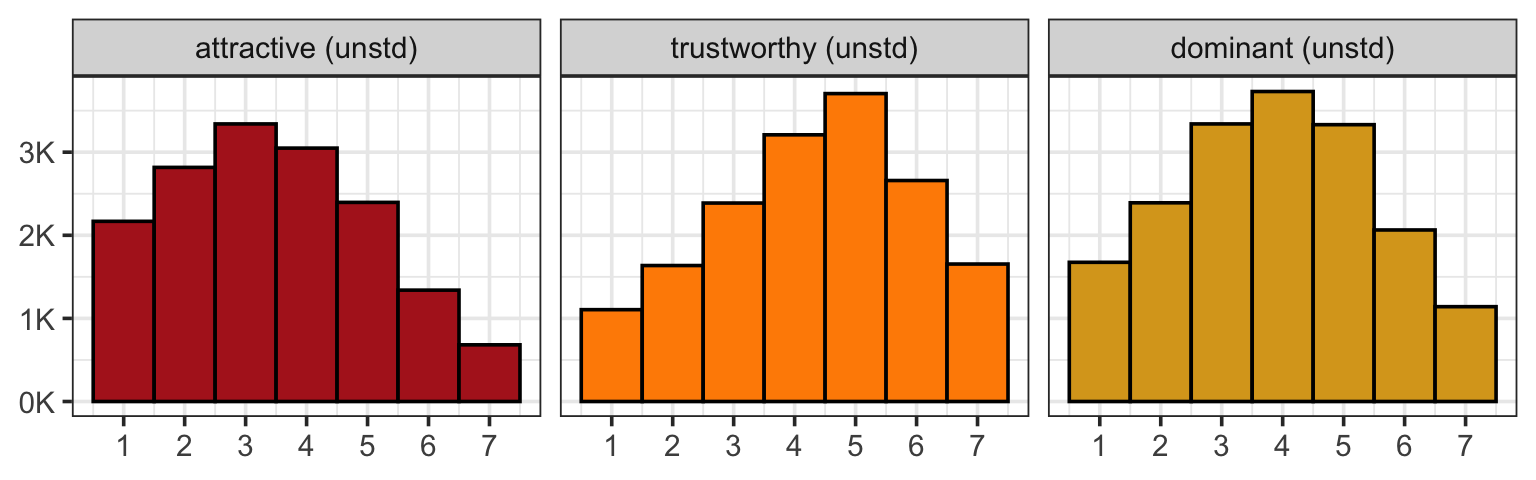
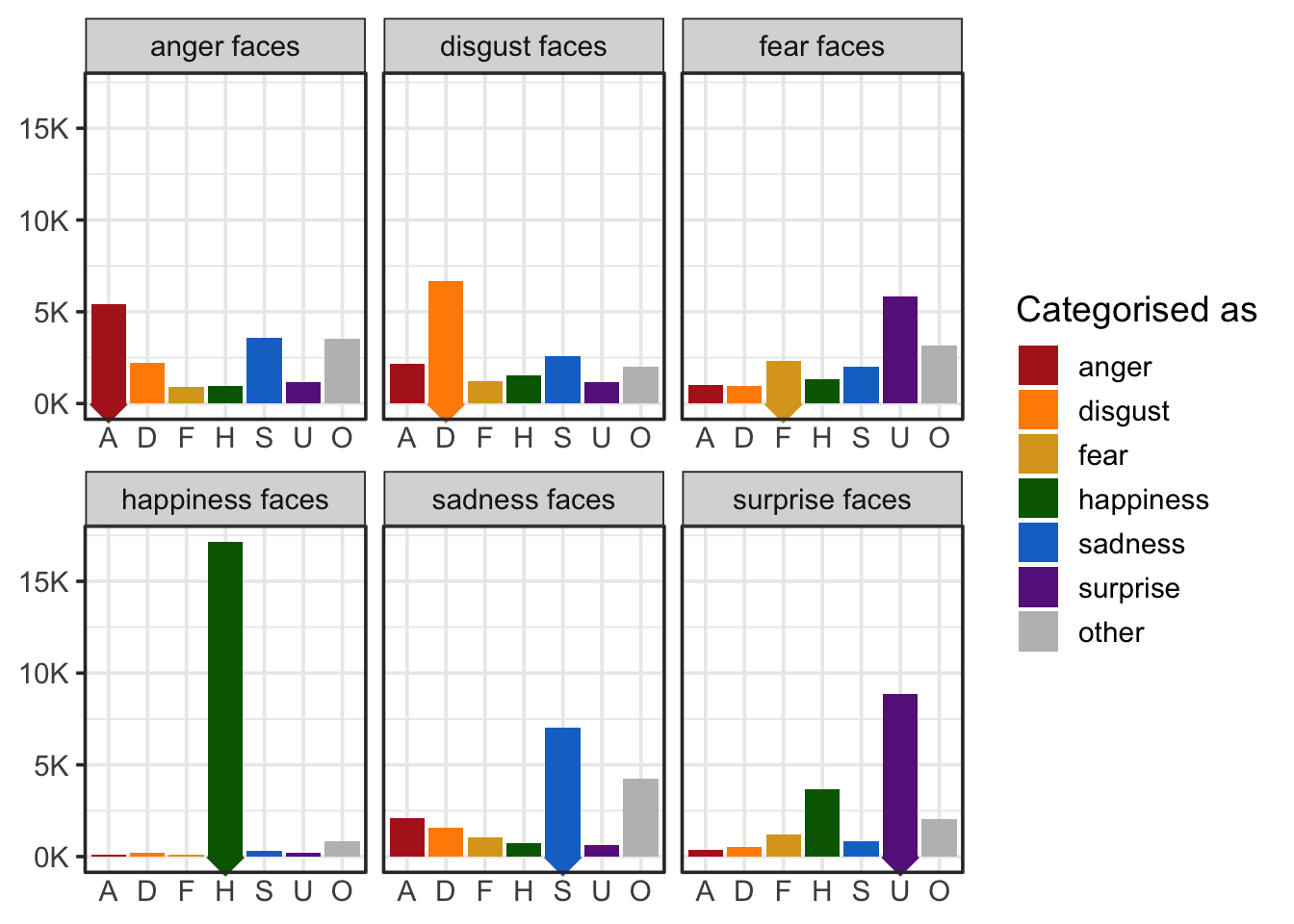
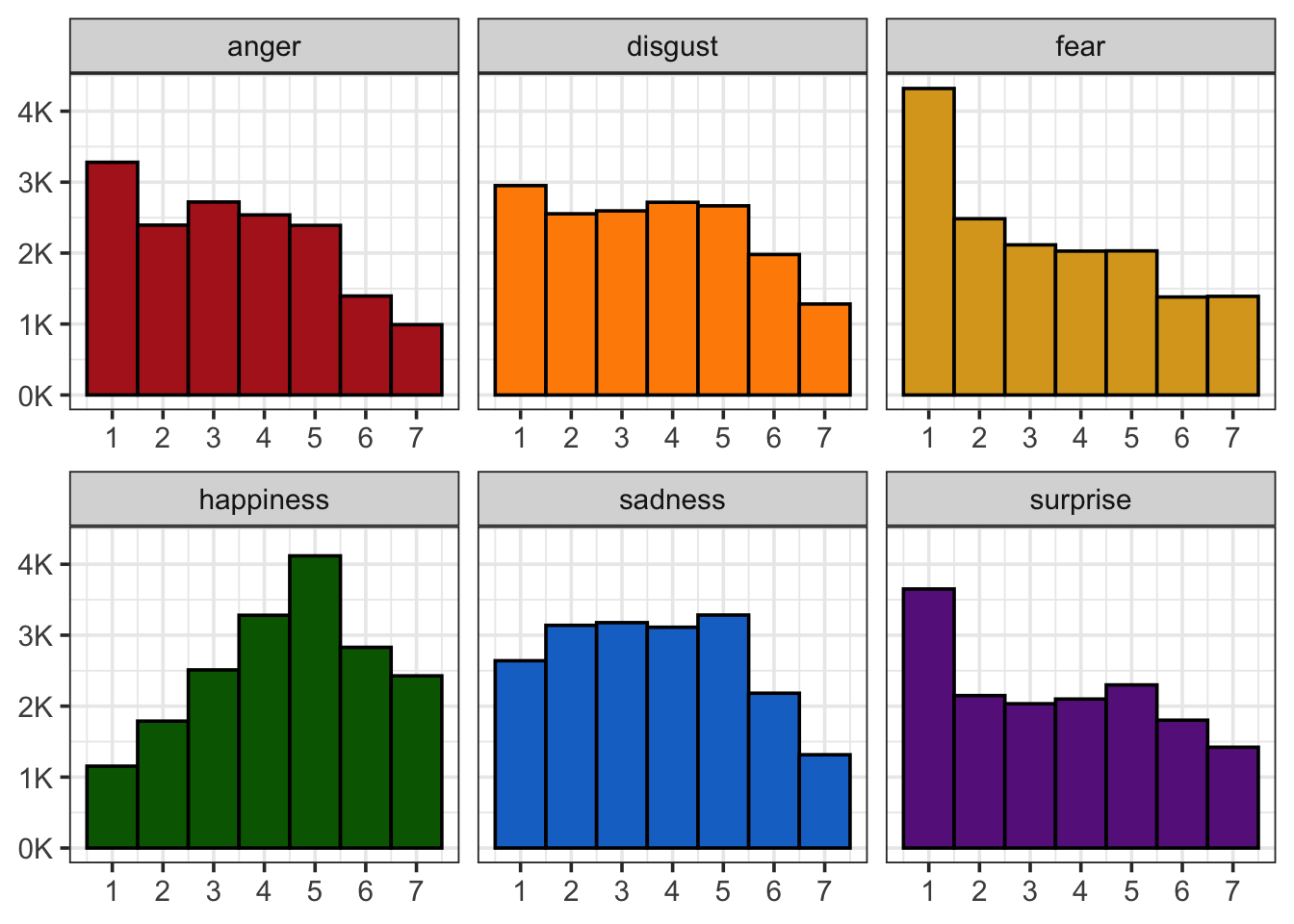
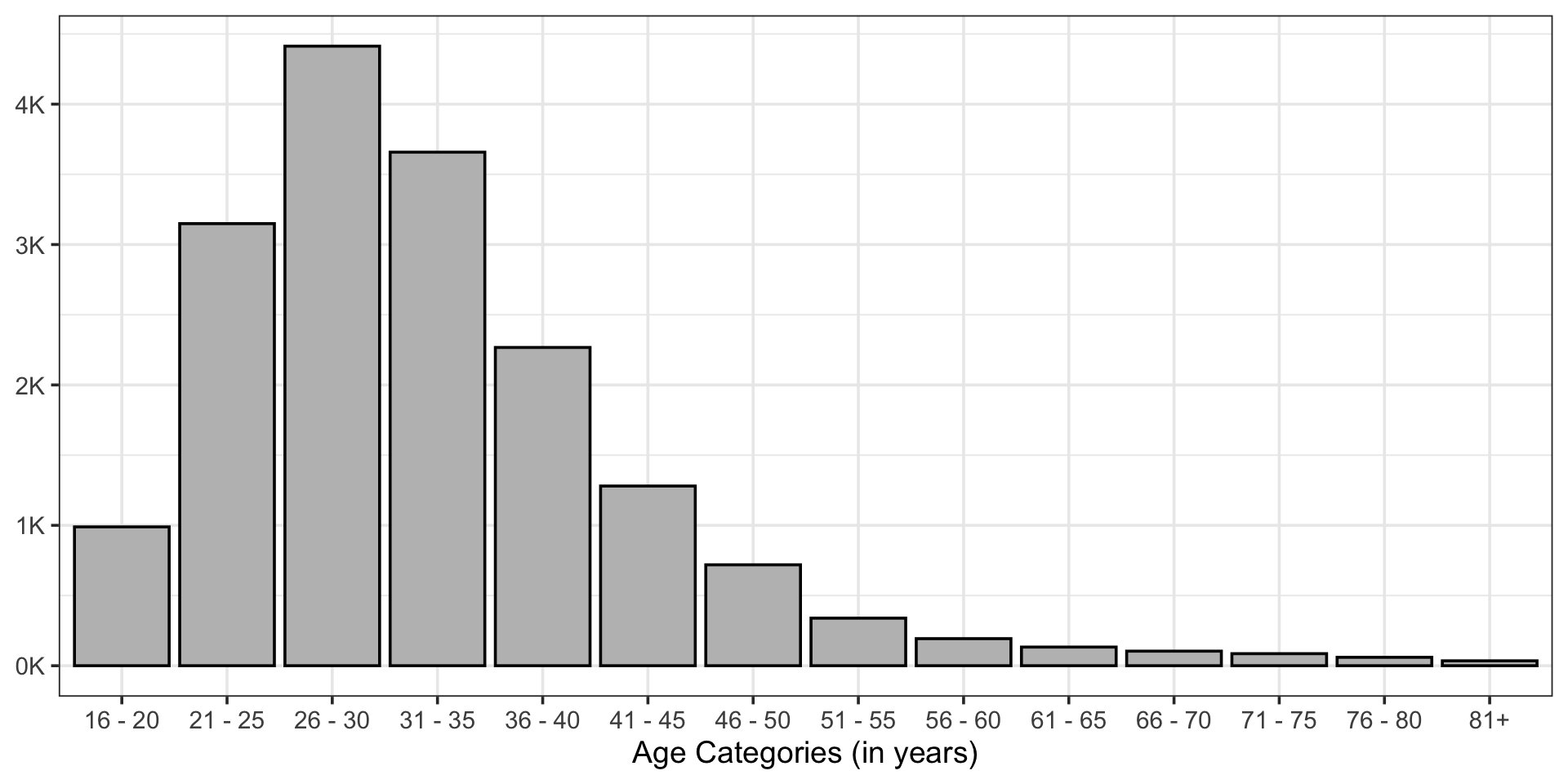
Bainbridge, W. A., Isola, P., & Oliva, A. (2013). The intrinsic memorability of face photographs.
Journal of Experimental Psychology: General,
142(4), 1323–1334.
https://doi.org/10.1037/a0033872
Bastanfard, A., Nik, M. A., & Dehshibi, M. M. (2007). Iranian
Face Database with age, pose and expression.
2007 International Conference on Machine Vision, 50–55.
https://doi.org/10.1109/ICMV.2007.4469272
Burton, A. M., White, D., & McNeill, A. (2010). The
Glasgow Face Matching Test.
Behavior Research Methods,
42(1), 286–291.
https://doi.org/10.3758/BRM.42.1.286
Chen, J. M., Norman, J. B., & Nam, Y. (2021). Broadening the stimulus set:
Introducing the
American Multiracial Faces Database.
Behavior Research Methods,
53(1), 371–389.
https://doi.org/10.3758/s13428-020-01447-8
Cook, R., & Over, H. (2021). Why is the literature on first impressions so focused on
White faces?
Royal Society Open Science,
8(9), 211146.
https://doi.org/10.1098/rsos.211146
Courset, R., Rougier, M., Palluel-Germain, R., Smeding, A., Jonte, J. M., Chauvin, A., & Muller, D. (2018). The
Caucasian and
North African French Faces (
CaNAFF):
A Face Database.
International Review of Social Psychology,
31(1).
https://doi.org/10.5334/irsp.179
Dawel, A., Krumhuber, E. G., & Palermo, R. (2025). Faking
It Isn’t
Making It:
Research Needs Spontaneous and
Naturalistic Facial Expressions.
Affective Science.
https://doi.org/10.1007/s42761-025-00320-1
Dawel, A., Wright, L., Irons, J., Dumbleton, R., Palermo, R., O’Kearney, R., & McKone, E. (2017). Perceived emotion genuineness: Normative ratings for popular facial expression stimuli and the development of perceived-as-genuine and perceived-as-fake sets.
Behavior Research Methods,
49(4), 1539–1562.
https://doi.org/10.3758/s13428-016-0813-2
DeBruine, L. M., Holzleitner, I. J., Tiddeman, B., & Jones, B. C. (2022).
Reproducible Methods for Face Research. PsyArXiv.
https://doi.org/10.31234/osf.io/j2754
DeBruine, L., Lai, R., Jones, B., Abdullah, R., & Mahrholz, G. (2020).
Experimentum. Zenodo.
https://doi.org/10.5281/zenodo.4010579
Ebner, N. C., Riediger, M., & Lindenberger, U. (2010).
FACES—
A database of facial expressions in young, middle-aged, and older women and men:
Development and validation.
Behavior Research Methods,
42(1), 351–362.
https://doi.org/10.3758/BRM.42.1.351
Freeman, J. B., & Johnson, K. L. (2016). More
Than Meets the
Eye:
Split-
Second Social Perception.
Trends in Cognitive Sciences,
20(5), 362–374.
https://doi.org/10.1016/j.tics.2016.03.003
Gao, W., Cao, B., Shan, S., Chen, X., Zhou, D., Zhang, X., & Zhao, D. (2008). The
CAS-
PEAL Large-
Scale Chinese Face Database and
Baseline Evaluations.
IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans,
38(1), 149–161.
https://doi.org/10.1109/TSMCA.2007.909557
Hehman, E., Xie, S. Y., Ofosu, E. K., & Nespoli, G. A. (2025). Assessing the
Point at
Which Averages Are Stable:
A Tutorial in the
Context of
Impression Formation.
Social Cognition,
43(5), 488–501.
https://doi.org/10.1521/soco.2025.43.5.488
Henrich, J., Heine, S. J., & Norenzayan, A. (2010). The weirdest people in the world?
Behavioral and Brain Sciences,
33(2-3), 61–83.
https://doi.org/10.1017/S0140525X0999152X
ImageMagick Studio LLC. (2024).
ImageMagick (Version 7.1.1) [Computer software].
https://imagemagick.org
Jack, R. E., Sun, W., Delis, I., Garrod, O. G. B., & Schyns, P. G. (2016). Four not six:
Revealing culturally common facial expressions of emotion.
Journal of Experimental Psychology: General,
145(6), 708–730.
https://doi.org/10.1037/xge0000162
Jones, B. C., DeBruine, L. M., Flake, J. K., Liuzza, M. T., Antfolk, J., Arinze, N. C., Ndukaihe, I. L. G., Bloxsom, N. G., Lewis, S. C., Foroni, F., Willis, M. L., Cubillas, C. P., Vadillo, M. A., Turiegano, E., Gilead, M., Simchon, A., Saribay, S. A., Owsley, N. C., Jang, C., … Coles, N. A. (2021). To which world regions does the valence–dominance model of social perception apply?
Nature Human Behaviour,
5(1), 159–169.
https://doi.org/10.1038/s41562-020-01007-2
Lakshmi, A., Wittenbrink, B., Correll, J., & Ma, D. S. (2021). The
India Face Set:
International and
Cultural Boundaries Impact Face Impressions and
Perceptions of
Category Membership.
Frontiers in Psychology,
12.
https://www.frontiersin.org/articles/10.3389/fpsyg.2021.627678
Langner, O., Dotsch, R., Bijlstra, G., Wigboldus, D. H. J., Hawk, S. T., & Knippenberg, A. van. (2010). Presentation and validation of the
Radboud Faces Database.
Cognition and Emotion,
24(8), 1377–1388.
https://doi.org/10.1080/02699930903485076
Lundqvist, D., Flykt, A., & Öhman, A. (2015).
Karolinska Directed Emotional Faces.
https://doi.org/10.1037/t27732-000
Ma, D. S., Correll, J., & Wittenbrink, B. (2015). The
Chicago face database:
A free stimulus set of faces and norming data.
Behavior Research Methods,
47(4), 1122–1135.
https://doi.org/10.3758/s13428-014-0532-5
Ma, D. S., Kantner, J., & Wittenbrink, B. (2021). Chicago
Face Database:
Multiracial expansion.
Behavior Research Methods,
53(3), 1289–1300.
https://doi.org/10.3758/s13428-020-01482-5
Martinez, J. E. (2025). Facecraft:
Race Reification in
Psychological Research With Faces.
Perspectives on Psychological Science,
20(1), 182–194.
https://doi.org/10.1177/17456916231194953
Meyers, C., Garay, M., & Pauker, K. (2024).
Hawai‘i Face Database: A racially and ethnically diverse set of facial stimuli.
https://doi.org/10.31234/osf.io/wde4b
Miolla, A., Cardaioli, M., & Scarpazza, C. (2023). Padova
Emotional Dataset of
Facial Expressions (
PEDFE):
A unique dataset of genuine and posed emotional facial expressions.
Behavior Research Methods,
55(5), 2559–2574.
https://doi.org/10.3758/s13428-022-01914-4
Oosterhof, N. N., & Todorov, A. (2008). The functional basis of face evaluation.
Proceedings of the National Academy of Sciences,
105(32), 11087–11092.
https://doi.org/10.1073/pnas.0805664105
Perrett, D. I. (2017). In Your Face: The new science of human attraction. Bloomsbury Publishing.
Roberts, S. O., & Mortenson, E. (2023). Challenging the
White =
Neutral Framework in
Psychology.
Perspectives on Psychological Science,
18(3), 597–606.
https://doi.org/10.1177/17456916221077117
Saribay, S. A., Biten, A. F., Meral, E. O., Aldan, P., Třebický, V., & Kleisner, K. (2018). The
Bogazici face database:
Standardized photographs of
Turkish faces with supporting materials.
PLOS ONE,
13(2), e0192018.
https://doi.org/10.1371/journal.pone.0192018
Schalk, J. van der, Hawk, S. T., Fischer, A. H., & Doosje, B. (2011). Moving faces, looking places:
Validation of the
Amsterdam Dynamic Facial Expression Set (
ADFES).
Emotion,
11(4), 907–920.
https://doi.org/10.1037/a0023853
Sneddon, I., McRorie, M., McKeown, G., & Hanratty, J. (2012). The
Belfast Induced Natural Emotion Database.
IEEE Transactions on Affective Computing,
3(1), 32–41.
https://doi.org/10.1109/T-AFFC.2011.26
Sutherland, C. A. M., Oldmeadow, J. A., Santos, I. M., Towler, J., Michael Burt, D., & Young, A. W. (2013). Social inferences from faces:
Ambient images generate a three-dimensional model.
Cognition,
127(1), 105–118.
https://doi.org/10.1016/j.cognition.2012.12.001
Sutherland, C. A. M., & Young, A. W. (2022). Understanding trait impressions from faces.
British Journal of Psychology,
113(4), 1056–1078.
https://doi.org/10.1111/bjop.12583
Tottenham, N., Tanaka, J. W., Leon, A. C., McCarry, T., Nurse, M., Hare, T. A., Marcus, D. J., Westerlund, A., Casey, B., & Nelson, C. (2009). The
NimStim set of facial expressions:
Judgments from untrained research participants.
Psychiatry Research,
168(3), 242–249.
https://doi.org/10.1016/j.psychres.2008.05.006
Třebický, V., Fialová, J., Kleisner, K., & Havlíček, J. (2016). Focal
Length Affects Depicted Shape and
Perception of
Facial Images.
PLOS ONE,
11(2), e0149313.
https://doi.org/10.1371/journal.pone.0149313
Třebický, V., Třebická Fialová, J., Bjornsdottir, R. T., & DeBruine, L. M. (2024).
A Grim Image: Considerations for Methods of portrait photography in psychological science. OSF Preprints.
https://doi.org/10.31219/osf.io/z4svb
Trzewik, M., Navon, M., Moran, T., Wardi, H., Langer, A., Hadad, B.-S., Sofer, C., & Reggev, N. (2025). The
Israeli Face Database (
IFD):
A multi-ethnic database of faces with supporting social norming data.
Behavior Research Methods,
57(7), 197.
https://doi.org/10.3758/s13428-025-02723-1
Workman, C. I., & Chatterjee, A. (2021). The
Face Image Meta-
Database (
fIMDb) &
ChatLab Facial Anomaly Database (
CFAD):
Tools for research on face perception and social stigma.
Methods in Psychology,
5, 100063.
https://doi.org/10.1016/j.metip.2021.100063
Yarkoni, T. (2022). The generalizability crisis.
Behavioral and Brain Sciences,
45, e1.
https://doi.org/10.1017/S0140525X20001685
Young, A. W., & Burton, A. M. (2017). Recognizing
Faces.
Current Directions in Psychological Science,
26(3), 212–217.
https://doi.org/10.1177/0963721416688114
Zebrowitz, L. (1997). Reading Faces: Window To The Soul? Routledge.